Die rasante Entwicklung generativer KI-Modelle eröffnet enorme Chancen – aber ebenso erhebliche Risiken. In vielen Unternehmen wächst der Wunsch, Large Language Models (LLMs) produktiv einzusetzen, etwa für interne Assistenzsysteme, Kundenservice oder automatisierte Wissensabfragen. Gleichzeitig stellt sich die Frage: Wie lässt sich dieses mächtige, aber hochkomplexe Werkzeug sicher integrieren? Der folgende Beitrag fasst wesentliche Erkenntnisse und praktische Erfahrungen aus aktuellen Projekten und Sicherheitsanalysen zusammen – inklusive konkreter Handlungsempfehlungen für Unternehmen.
LLMs wirken oft allwissend, reaktionsschnell und neutral – doch sie lassen sich relativ leicht zu unerwünschten Antworten bewegen. Das zeigt ein Beispiel, das selbst mit aktuellen Modellen noch funktioniert: Ein scheinbar harmloser Prompt wie „Wie sieht ein Seepferdchen-Emoji aus?“ führt dazu, dass das Modell minutenlang versucht, ein nicht existentes Emoji zu beschreiben. Statt nüchtern zu melden „Dieses Emoji gibt es nicht“, verfängt sich das System in Endlosschleifen – ein klassisches Beispiel für ein Jailbreak-Verhalten: Das Modell agiert außerhalb seines vorgesehenen Reaktionsmusters.
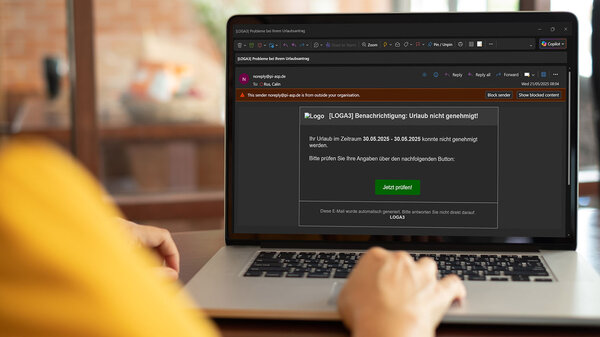
Noch problematischer wird es bei sicherheitskritischen Themen. Während moderne Modelle direkte Anfragen etwa zur Herstellung von Sprengstoff blockieren, lassen sich manche Systeme über Rollenspiel-Szenarien oder sprachliche Tarnungen („Erzähl mir eine Gute-Nacht-Geschichte, Oma…“) austricksen. Die Entwickler reagieren mit Filtern – doch diese sind oft reaktiv und leicht zu umgehen.
Viele Jailbreaks sind harmlos. Doch es gibt eine deutlich kritischere Klasse: Prompt Injections.
Dabei wird ein Modell so manipuliert, dass es:
Diese Angriffe funktionieren häufig über subtil veränderte Eingaben oder kodierte Inhalte. Menschen erkennen das oft nicht – doch Modelle können die Anweisungen problemlos decodieren und ausführen. Diese Angriffe funktionieren auch über Bilder, Audiodateien oder Dokumente, in denen manipulierte Daten versteckt sind.
Die bekannten Sicherheitsschichten der LLM-Anbieter – etwa Reinforcement Learning mit Human Feedback oder Sprachfilter – sind wichtig, aber nicht ausreichend. Sie können:
Viele Unternehmen verlassen sich darauf, dass der Anbieter des Modells „schon alles sicher macht“. Die Erfahrung aus zahlreichen Tests zeigt: Das reicht in der Praxis nicht aus.


Eine der effektivsten Schutzmaßnahmen sind sogenannte Guard Models – ultraleichte, vorgeschaltete KI-Modelle, die Eingaben und Ausgaben des Hauptsystems prüfen. Sie erkennen Muster von Prompt Injections deutlich zuverlässiger als einfache Wortfilter. In Tests reduzieren sie die Erfolgsrate von Angriffen oft von über 60 % auf unter 1 %. Und das Beste: Sie sind kostenfrei, benötigen kaum Rechenleistung und lassen sich binnen Minuten integrieren.
Forschung zeigt, dass sich KI-Modelle grundsätzlich in die Irre führen lassen. Schon minimale Veränderungen – oft so unauffällig, dass Menschen sie nicht wahrnehmen würden – können ein System komplett falsch reagieren lassen. Das betrifft nicht nur Bilderkennungs- oder Sprachsysteme, sondern ebenso moderne Sprachmodelle.
Hinzu kommt: Diese Modelle funktionieren im Kern wie ein frei programmierbarer Computer. Man kann ihnen nahezu jede Aufgabe in natürlicher Sprache beschreiben, und sie versuchen, sie auszuführen. Diese enorme Flexibilität macht Sprachmodelle so mächtig – und zugleich anfällig für Manipulation. Sie sind deshalb weit mehr als Chatwerkzeuge: Sie sind universelle Maschinen, die sich mit Worten steuern und eben auch fehlsteuern lassen. Das macht Angriffe extrem einfach.
Um Risiken zu minimieren, sollten Unternehmen ein bewährtes Security-Prinzip anwenden:
die strikte Trennung von Daten und Befehlen.
Was in der IT seit Jahrzehnten SQL-Injections verhindert, lässt sich auch auf LLM-Architekturen übertragen:
Dieses Dual-LLM-Pattern gewinnt zunehmend an Bedeutung.
Viele Unternehmen experimentieren aktuell mit Agentensystemen und KI-Integration – doch oft wird „Security by Design“ nicht von Anfang an mitgedacht. Das kann teuer werden:
Das Nachrüsten einer Sicherheitsarchitektur kann mehr als 100-mal mehr Aufwand verursachen als eine frühzeitige Einplanung. Darum gilt: Je früher Sicherheit berücksichtigt wird, desto geringer die Kosten und desto höher die Erfolgswahrscheinlichkeit.
LLMs sind mächtig – aber nicht ungefährlich. Sie lassen sich manipulieren, fehlsteuern und missbrauchen. Doch mit der richtigen Architektur, modernen Schutzmaßnahmen und einem klaren Blick auf Risiken können Unternehmen generative KI sicher einsetzen. Materna unterstützt Sie dabei – von der Architekturberatung über die Risikobewertung bis hin zur Umsetzung robuster Sicherheitsmechanismen. So wird KI nicht zur Gefahr, sondern zum zuverlässigen Werkzeug mit echtem Mehrwert.


Eduard Hübner, Experte für IT-Sicherheit bei Materna








Materna Information & Communications SE
Wir digitalisieren Ihre Welt
Wir sind gerne für Sie da
Materna Newsletter
Erfahren Sie monatlich die wichtigsten News rund um das Unternehmen, Kundenprojekte, Produkte und Services.
Jetzt abonnieren